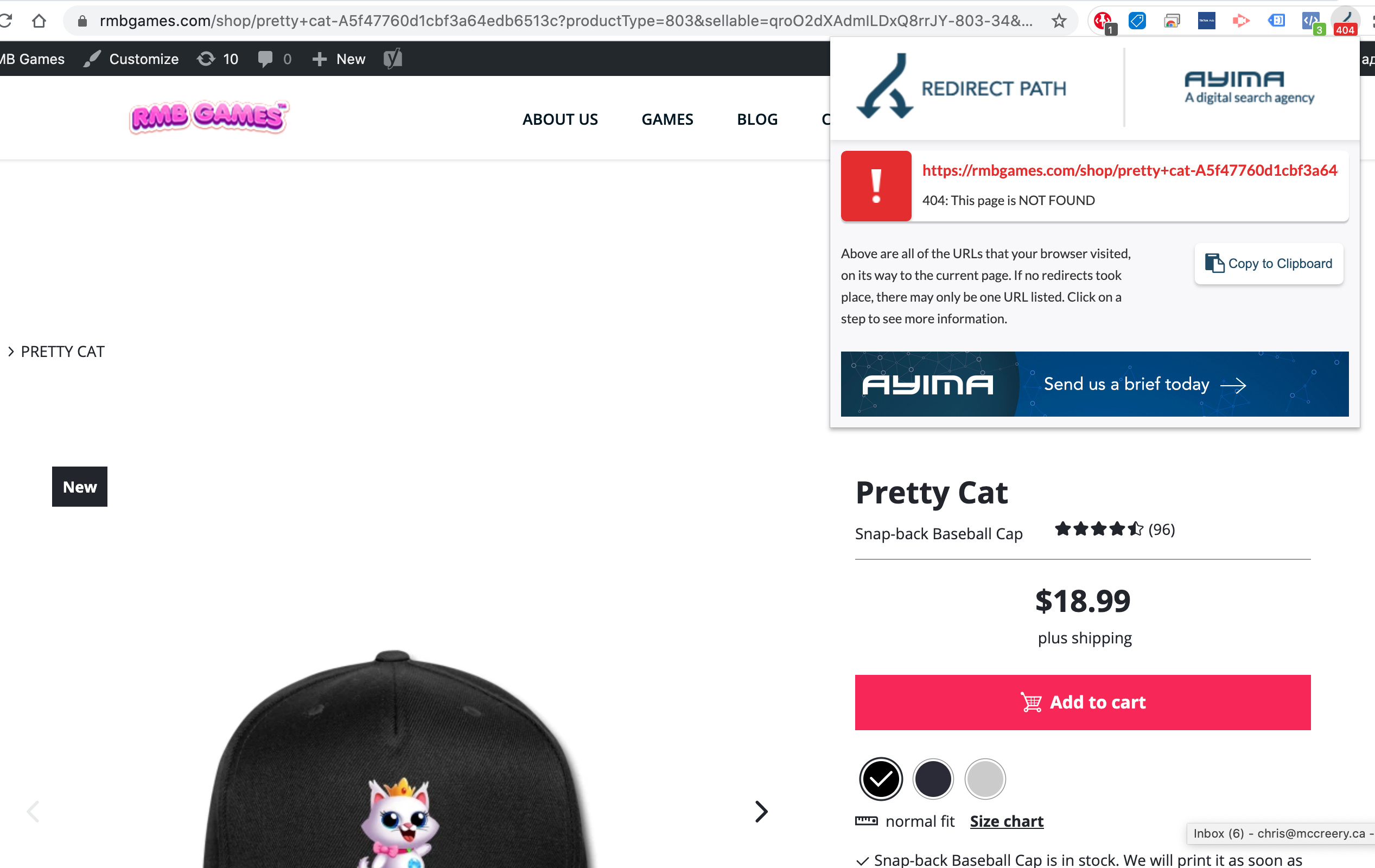
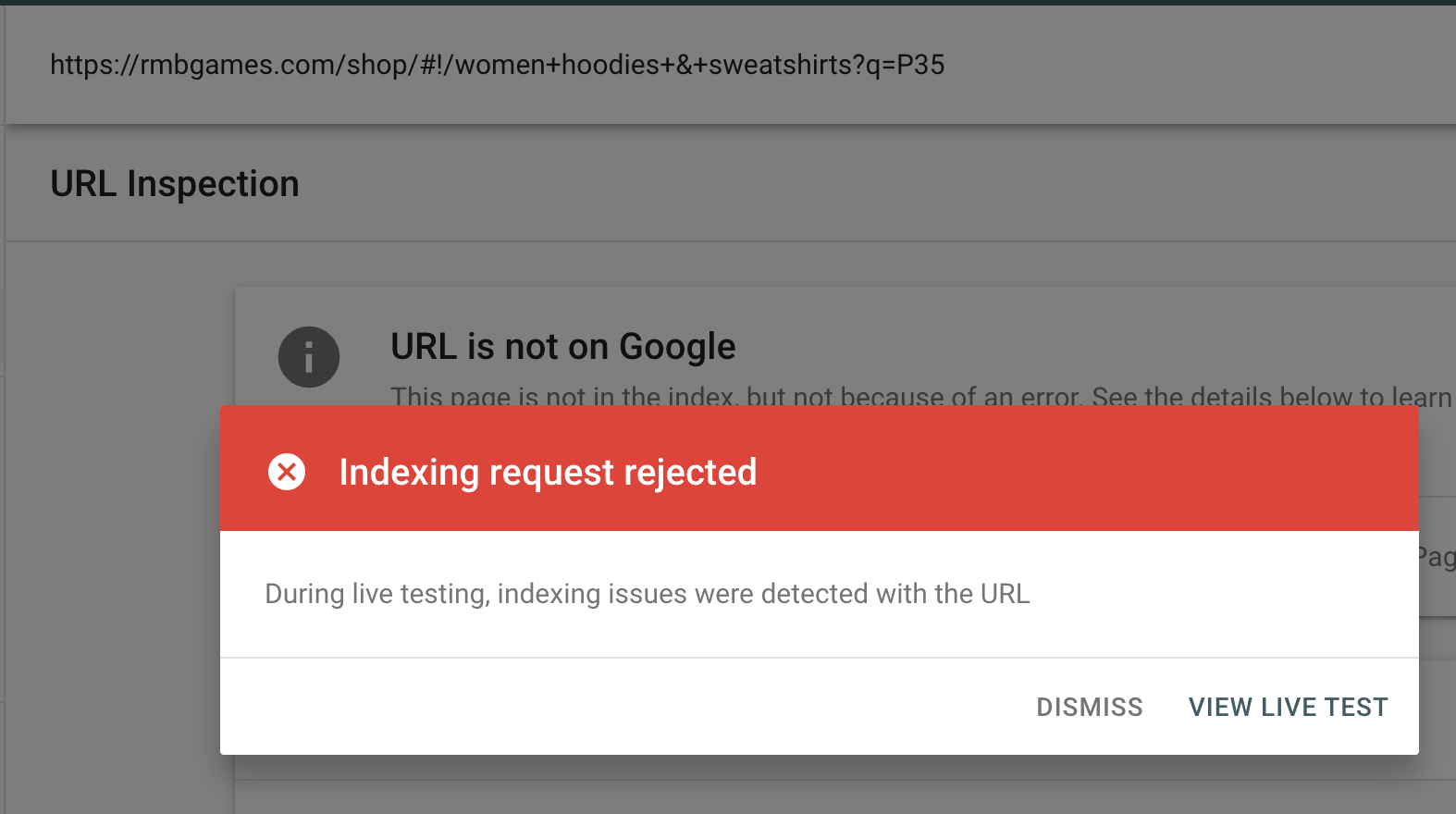
Sorry for my late response up on that topic
At first, to the question of crawling.
Our DEV team is supervising the indexing progress of shops in general. We see clear patterns that the Google bots are able to crawl your pages, even if we are not 100% sure why they cannot access the information in some cases.
So be sure they´ll find their way through.
Removing the hashbang manually is and will always be a use case for advanced users. We do not give advice regards that solution, as the support mostly transforms into an endless back and forth. 
Indexing:
We are actively deciding against an indexing off each and every page and list page of all shops.
Here´s the why: For Google, the entity of all active shops consists of an identical content structure.
Means, independent from each shop´s topic and the designs offered inside, Google Bots recognize the deep link structure for every shop as the identic. Therefore, they most likely only crawl and rank content that is really well maintained by the shop owner.
How to overcome this?
My advice here is clearly to use the blessing of your own domain by building user-relevant content around your shop. That´s what Google is looking for.
Means, you should start building a content home. Create Landingpages for your best niche designs. Do storytelling about your shop, your brand, etc.
This is where the SEO effect kicks in and where a sitemap really makes sense.
Not a sitemap for your shop, only… but for your website! That is the answer I can give here.
My Tip:
Anytime you upload a new design, you can release a new landing page for it. If you have, feel free to write blog content and link to your LPs where possible.
So your website might gain much more link juice than your stand-alone-shop could ever do.